For this project, I self-host a media server with Jellyfin, set up Tailscale to securely access my server from anywhere, and write a script to quickly download Critical Role episodes to the media server.
Background
A couple of years ago, I watched the first season of Critical Role. If you haven’t heard of it, the show features well-known voice actors playing Dungeons and Dragons. They’re all great at voices, accents, impressions, storytelling, and improv, and it makes for an exciting show!
Each episode is anywhere between 2 and 4 hours long (it was originally a weekly livestream), and the first season has about 115 episodes. It took me a while to get through it, mostly while walking across campus during my master’s degree.
I decided to watch the second season recently, but wanted a better way to sync my progress between devices, as I’ll often listen to the show while driving or in the background on desktop. YouTube works, but doesn’t always sync progress properly, and I didn’t enjoy scrubbing through 4-hour long videos when progress didn’t sync. There is a podcast, but it doesn’t have the video, it’s missing some content, and I found it frustrating to scroll through my podcast app to find the show again whenever I wanted to continue listening.
The goal: Critical Role Season 2, properly synced between devices. Continue watching/listening with as close to one click as possible.
The plan
At a high level, this is how I approached this project:
- Set up a server
- Install Tailscale for secure access
- Install Jellyfin for the media server
- Write a script to easily download show episodes into Jellyfin
Acquiring a server
For the server, I decided to rent a VPS. I could have used an old computer, but I’ve already done so on past projects and didn’t want to do that here.
I’d normally use something like Linode or DigitalOcean, but media servers need storage, and storage is expensive on these platforms. However, I recently saw a video from Dax Raad where he explains his remote development setup. In the video, he recommends looking for VPS providers with desktop CPUs rather than server CPUs. Following this advice, I found Oplink and rented a server with a Ryzen 9950x (one vCPU), 4 GB memory, 100 GB of NVMe storage, and 10 TB of data transfer - all for $7.95 a month.
You might argue that this is a bit expensive for one hobby project, or overkill for a media server, and you might be right! However, I can also use this server for other projects. Having a server that I manage allows me to build low-scale projects just for myself in the spirit of this post. I’ve set up Syncthing to sync files across all of my devices, and have ideas for future projects that this enables. Having a personal server feels empowering, and I recommend it for any software engineer looking for side-project inspiration.
Initial setup
The server came with Alma Linux, which is fine. In the future it’d be nice to run NixOS.
The first thing I did to set up the server was install
Tailscale. After installing, I used ufw to block
public network access, so that the server would only allow connections from
inside the Tailscale network.
I also installed Docker and Nix. Docker for the Jellyfin server, and Nix for my download script (more on this later).
Setting up Jellyfin
Jellyfin was trivial to set up with Docker Compose. I created a
docker-compose.yml with the following content, and started the service with
docker compose up -d.
services:
jellyfin:
image: jellyfin/jellyfin
container_name: jellyfin
network_mode: 'host'
volumes:
- /root/jellyfin/config:/config
- /root/jellyfin/cache:/cache
- /media:/media
restart: 'unless-stopped'
Importantly, /media:/media creates a bind mount, binding the /media
directory on the host to the /media directory in the container. When I
download episodes, I can put them on /media on the host for the Jellyfin
server in the container to serve them.
After starting the container, I could access my media server from a browser on any of machines connected to my Tailscale network:
Accessing the media server on iOS
To access the server on my phone, I installed Tailscale and a Jellyfin client. After trying a few Jellyfin clients, I landed on SenPlayer, which has a nice UI and an option to continue playing media in the background and when the screen locks.
Downloading episodes
Next, I had to download the show episodes. With only 100GB of storage, I couldn’t download the entire show, and wanted a tool to allow me to easily pre-download episodes into the media server. For example, after finishing episode 10, I’d like to easily download episodes 11–20.
A web app would be cool, but probably overkill. In theory, I’d only be using this tool a few times, a few months between each use. A script would be enough to accomplish this.
After a few iterations, I ended up with the script
here.
To be honest, I probably should have used something other than bash for this,
but it’s good for the purpose it serves. I use this script by sshing into the
machine whenever I’m close to finishing the episodes I’ve downloaded.
The script uses gum for the TUI frontend
and yt-dlp to download episodes from
YouTube. yt-dlp has options for including
SponsorBlock data, allowing me to add chapter
data that Jellyfin can use to skip the intro sequence and intermission for each
episode!
I also use shell.nix for dependencies. It’s a nice balance for this
lightweight script: not a full Docker container, but enough to allow me to
manage dependencies in a sane way.
Here’s a demo. I can select multiple episodes, but just download episode 12 here.
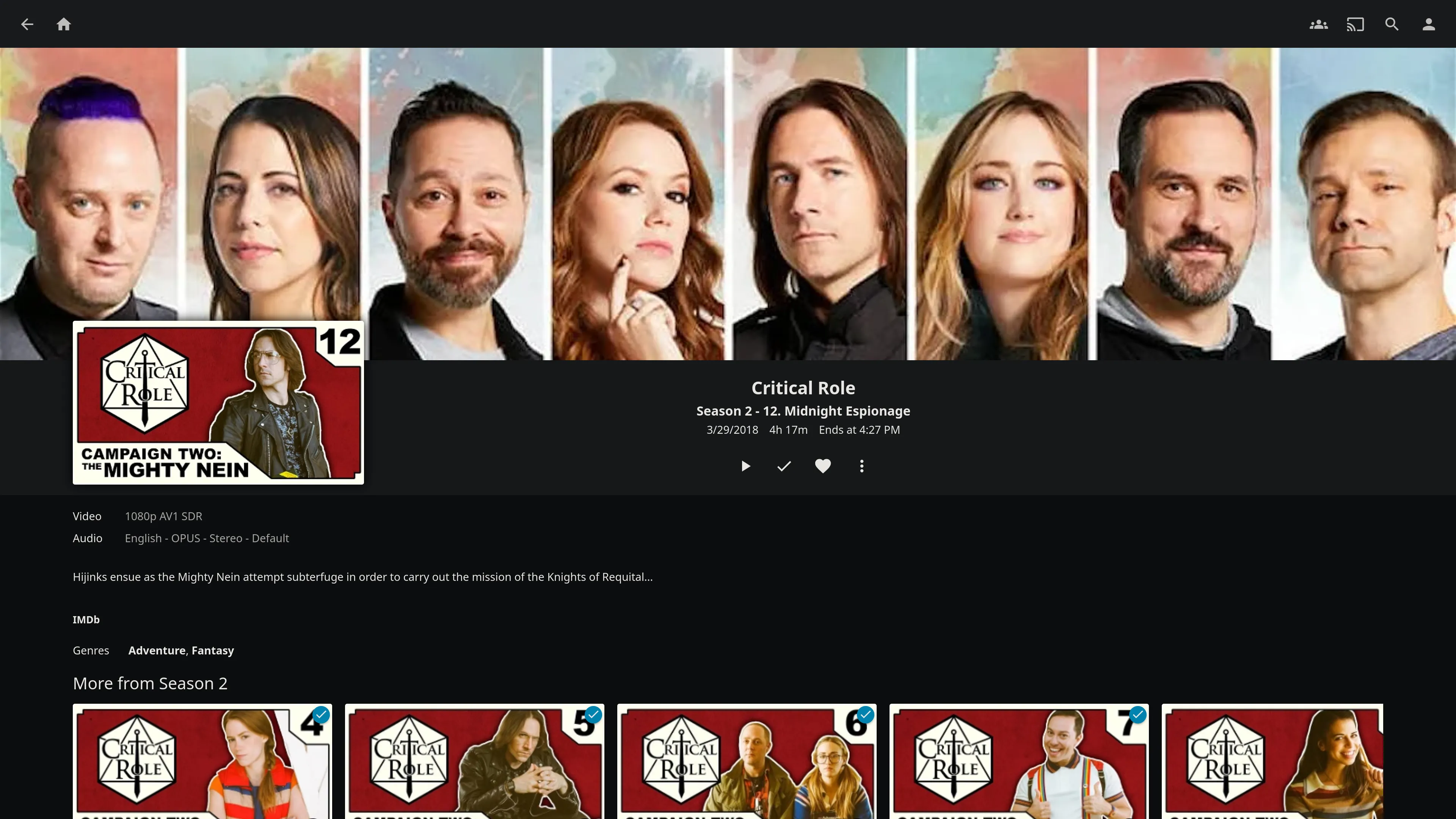
After running the script, I can see episode 12 in my Jellyfin library, with the metadata (episode title, thumbnail, description) automatically added:
It also shows on the mobile client:
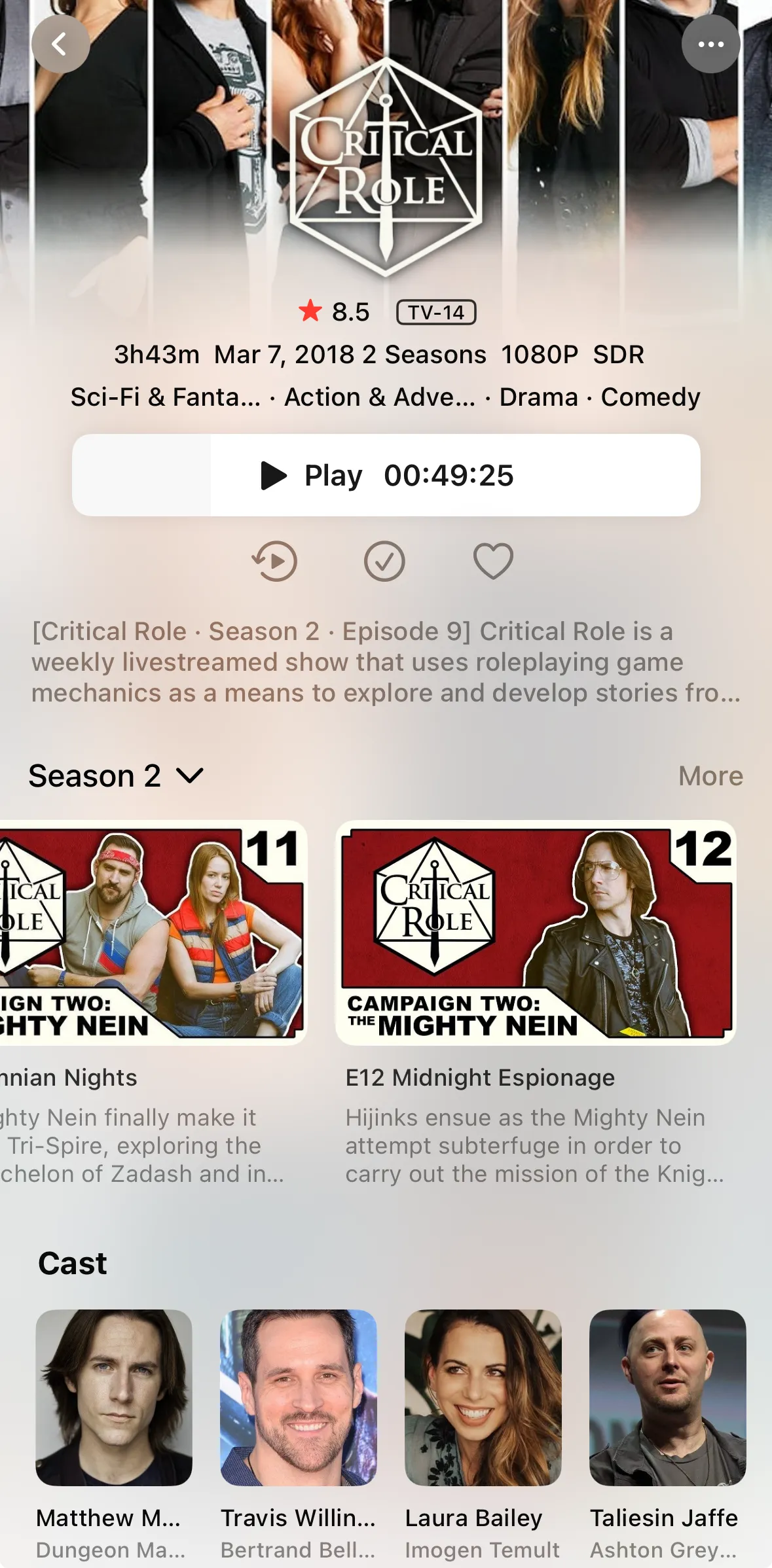
The YouTube playlist has videos in the middle of the playlist, like short episodes where the players roll for new stats after leveling up. I wanted to see these in the order they’re presented in the playlist without throwing off the episode numbers, as Jellyfin uses episode numbers to pull metadata. Luckily, there’s a corner of the Jellyfin docs which outlines how to do this by treating those episodes as “specials” and adding metadata with an NFO file. The script handles this as well.